
Put that $337k back in your pocket — use a purpose-built model for cyber
Introducing LogLMs
Pro tip — skip the blog, and try it out now. Head over to your Snowflake account and search in the marketplace for Tempo. Grab our NativeApp — preloaded with data from the Canadian Institute of Cybersecurity. Take it for a spin, check out how it fits into your SIEM, and the context it provides to your security team. You can also just follow this link.
The rise of large language models (LLMs)
In the last blog I shared a little bit about why we flirted with GNNs. In this blog I dive into our true love affair with transformers. If I had to pick one moment, it would be a problem set from Stanford’s CS330. Long story short, we built a model that was trained on many languages, to be able to recognize handwriting samples; it worked well — offer a few new scribbles and it could discern what language you were attempting to write. But that was not what was exciting — what was really exciting was adapting it with a few samples of a new language. Imagine that — you have some software running on your janky Azure instance and then you feed it some examples of a new language and immediately it is able to apparently identify the entire language. This is an example of few shot learning and the ability of these models to generalize. Once you see it, you cannot unsee it.
Despite being hugely impressed by LLMs, and by the role of transformers in transfer learning, I diverged from LLMs themselves as the foundation of our solution. Once again, listening to the needs of cybersecurity users, we decided that LLMs alone could not meet our needs, at least for the next several years. We ran into a few ways that LLMs are challenged to be useful as the foundation of a new approach to cybersecurity, one with far better accuracy at discerning potential attacks, including hallucinations, costs, and accuracy.
First, because LLMs are generative they are far better at tasks like content generation where the risk of **hallucination** can be tolerated and controlled. In cybersecurity, where precision is critical and companies are already wrestling with floods of false positives from difficult to maintain rules based meshes of indicators, additional false positives help no one.
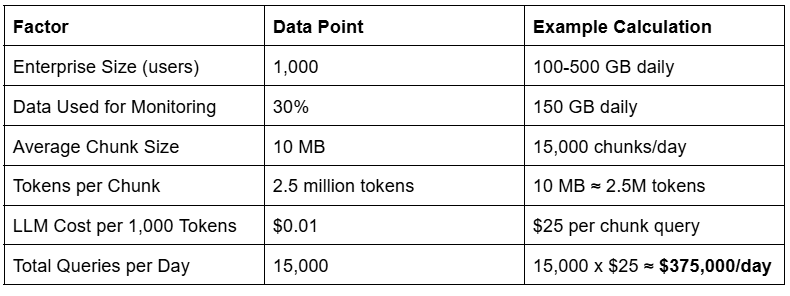
Second, operating **state-of-the-art LLMs at scale** is cost-prohibitive when applied to environments like cybersecurity, where monitoring and scalability are essential. Think about prompting OpenAI constantly with enormous prompts to provide context, in a rolling window. The costs that would entail reflect the massive computation going on to provide any insight; running an OpenSource LLM does not get around this issue — you would need large clusters to deal with the sorts of data we work with in cybersecurity and observability monitoring.
Our back-of-the-envelope estimate is that a medium enterprise of 1,000 users and devices could be monitored, somewhat, using LLMs at a cost of approximately $375,000 per day. Note that the data volumes increase exponentially as the network complexity increases, so a 10,000 node network would likely be 100x or more larger in terms of Netflow data and hence closer to $37 million per day.
Third, even if you could deal with the potential hallucinations and the substantial cost, our experiments have convinced us that LLMs are still unlikely to see the specific patterns of attacks as well as purpose-built models. Because LLMs are trained on broad, diverse datasets, they are generalists rather than specialists. Detecting rare, specific events like cyberattacks requires **specialized understanding** of logs, system behaviors, and threat signatures. LLMs lack the targeted precision required for anomaly detection, where minute deviations are significant. And, at least in our experience, even the few-shot learning superpowers of LLMs that first blew my mind are insufficient to overcome these challenges.
Introducing LogLMs: A purpose-built alternative
With no further ado, here is the direction we went in. We essentially built a cousin of LLMs, one purpose-built for cyber security.
LogLMs are designed specifically for analyzing predictably structured or semi-structured data such as log files. Leveraging this predictability to infer normal from the training data, LogLMs are extremely good at anomaly detection. They don’t look for needles in the haystacks; LogLMs burn the haystack down until only the needles remain. This is possible because unlike LLMs, which are **decoder-focused** and generative, LogLMs are **encoder-only** models. Their purpose is to **process and interpret existing patterns** rather than generate new content.

Note that if you have been so burned by anomaly detection that you believe that it will never work in cyber security, a) you are wrong and b) I do feel your pain — and I wrote a blog for you. Take a look for an explanation of why anomaly detection has earned a mixed reputation in cyber security. Your feedback is welcome and much appreciated.
Now a little more about the care and feeding of LogLMs. We pre-train them with self-supervised learning on logs from systems, networks, and security events. Their understanding of normal which is derived from this specialized training makes them particularly adept at identifying deviations or anomalies quickly and efficiently. A variety of academic studies as well as our own work with development partners confirms that LogLMs flag abnormal behavior in real time, with high precision and a low level of false positives.
One reason that LogLMs are accurate is that, as mentioned above, LogLMs are pre-trained with self-supervised learning. A simple way to understand this is that unlike traditional ML and of course rules-based systems, which require labels, self-supervised learning can train by masking known good data and learning to get better and better at predicting that masked data. In the case of security, this is important because actual attack patterns are hard to find whereas logs that contain mostly normal behavior are plentiful.
As an aside, don’t get it twisted. Labels of known attacks are really valuable. We find enormously useful the patterns of attacks gathered as a part of Mitre Att&ck for example. But attempting to train a model on attack patterns is a recipe in frustration. Not only are there not enough samples, that approach is inherently backward facing. Even if you can find enough labels, training only on attacks gives the initiative to the attacker.
In fact, there is some evidence that attackers are using LLMs to author novel attacks, including modifications of attacks so they avoid backward looking pattern-based identification of attacks. LogLMs are able to see any deviation from the normal, and thereby able to see new attacks as well as known attacks. LogLMs — when used along with other software I’ll discuss in yet another blog — give the initiative back to the defender.
Last but not least, LogLMs are much smaller and more efficient than running a general purpose LLM. For most customers our Tempo LogLM uses just a GPU or even a CPU when performing inference. That would be impossible for traditional LLMs.
What do LogLMs need to be successful?
While LogLMs present a promising alternative to LLMs for anomaly detection, building them and operating them so that they boost the productivity and security of users takes substantial innovation and investment.
FIrst, the design and development required to build LogLM from the ground up is extremely challenging. The software engineering required includes building a transformer and self attention based model that is able to ingest log data. I’ll write more about the details of our design in the future.
For now I’ll share just one detail — that should make you go “hmm.” If you set out to build a LLM today, you generally grab from Hugging Face a vocab and even an embedding model. Well, there isn’t a model sitting on Hugging Face that is broadly adopted for turning enterprise security logs into vocabulary or for embedding them into vectors. Side note — if you want to collaborate with us to build such primitives in the open, please get in touch or just head over to the beginnings of a community in a Github we set up initially to house the Mitre Embed RAG project we helped to create and sponsor: https://github.com/deepsecoss
Secondly, these models must be pre-trained. We are fortunate in that we have partnered with one of the largest financial institutions in the world. This visionary organization has given us the opportunity to use their computing power and their log data to build extremely powerful models that can also generalize. We will be sharing more about this design partnership in the weeks to come. While self-supervised pretraining does not require labels — it does require lots of data and GPUs. When you use our Tempo LogLM you are benefiting from the data and compute power of a set of enlightened users that have given the flywheel of model improvement an enormous initial push.
Third, context is all important to confirm and triage potential attacks. Again, we will be sharing more about our approach in the future. LogLMs themselves, along with other approaches including RAG models like the MitreEmbed mentioned above, can be used to deliver more context. And the LogLM can, if designed with this use case in mind, pass along context such as the underlying questionable sequences that caused an alert, the entities impacted, and of course incredibly fine grained information about the pattern and time of suspicious events.
Conclusion:
LLMs are invaluable for generative tasks, where adaptability and content creation are paramount. And they can help downstream when triaging and responding to potential incidents. However, they are ill-suited for incident detection in cyber security. LLMs won’t sure-up the foundations of cyber security, they alone cannot address the dry rot of horribly inaccurate incident identification.
In contrast, **LogLMs** are built specifically for this purpose. Their focus on recognizing normal to make deviations obvious and their efficiency in handling log data make them an easy way to enable defense in depth in any enterprise or service provider. We are also seeing success is using the LogLMs to learn and highlight the context necessary for security operations teams to confirm and triage potential incidents.
In a blog written with the input of friends at Snowflake, we introduce you to how we harness LogLMs, along with LLMs playing their role, to boost the productivity of security operations while better protecting enterprises by running as a Snowflake Native App. This blog dives into the architecture of the system on Snowflake. Highly recommended if I do say so myself.
Your feedback is needed and appreciated! Am I right, that purpose-built AI such as our LogLMs can return the initiative to defenders, and give us an ever-improving solution for collective cyber security defense?
What else would you like to understand about this approach?
Grab the wheel and gun the engine:
You can see how we use our LogLMs along with other software to return initiative to the defenders by heading over to Snowflake. As mentioned above, we fueled the tank with demo data — take her out for a spin! You can find Tempo here or just search for Tempo on the Snowflake Marketplace.
