
When we introduce our Tempo LogLMs — we often explain that Tempo is a Foundation Model. But what is a foundation model? And is there a difference between cybersecurity foundation models and foundation models used in cybersecurity? In this blog, I briefly discuss those subjects.
Yes, I am not a neutral observer here. That said, I also deeply believe we must immediately get our act together in cybersecurity and that only openness and candid conversations — and maybe some changes to industry structure that I discuss in my blog Platforms are the Problem — will get us on a more rapid learning curve. Today, I fear, the adversary is learning faster than we are.
What Is a foundation model?
A foundation model is typically a large-scale, pre-trained neural network that can be adapted — or “fine-tuned” — to a wide range of downstream tasks with minimal incremental training. Many large language models (LLMs), such as ChatGPT, are classic examples: they’re trained on huge corpora of text and can be applied to numerous text-based problems.

That said, foundation models aren’t limited to purely generative LLMs. An encoder‑only approach such as our Tempo — one focused on learning powerfully nuanced relationships found in underlying data rather than the generative tasks of decoder models such as freeform text generation — can also be a foundation model if it has learned powerful representations that generalize across many tasks. The central idea is strong generalization, which enables the model to:
- Adapt quickly to new data.
- Transfer knowledge from one environment to another.
- Serve as a robust “base” for multiple tasks in complex domains.
In practice, we measure the ability of a model to generalize by establishing a baseline of performance and then testing the ability of the model to equal that performance when exposed to a new distribution of data. In the case of Tempo — we seek to adapt in less than one hour when examining new data including new log sources while running on Snowflake; I believe this is an unprecedented speed of adaptation for a cybersecurity model.
Why does this matter for cybersecurity?
Cybersecurity is one of the most dynamic, data-rich fields, with new threats surfacing daily. A16z’s recent discussion of foundation models for cybersecurity highlights the power of large models in cybersecurity. The focus of their podcast, though, is how useful it might be to apply foundation models pre-trained with written text and code to the cybersecurity domain. They do not discuss the potential of foundation models pre-trained with security log data.
Thankfully, researchers are publishing an increasing stream of useful papers. Just a few minutes on your favorite deep research LLM will show a number of state-of-the-art results across various cybersecurity domains.
Promising purpose-built foundation models for cybersecurity are typically encoder-focused, precision-driven systems — ones that, unlike LLMs, don’t generate new data but rather excel at:
- Detection of anomalies or threats in complex, varied log data.
- Correlation of signals across time, endpoints, and telemetry sources.
- Adaptation to novel threats without expensive, and manual feature engineering.
Security foundation models compared to other approaches
Other advanced techniques, such as graph databases or graph neural networks (GNNs), show promise in identifying relationships within security data.
However, their ability to generalize to new data sources and new threats has been limited. Foundation models, by contrast, aim to learn a universal representation of text or logs that can quickly adapt to changing conditions.
I previously wrote about why we decided not to use GNNs at DeepTempo in a prior blog — and an inability to generalize was certainly an important factor.
The importance of generalization
Below are four reasons why generalization is essential for modern cyber defense:
- Immediate Value: A pre‑trained model can deliver insights immediately, with minimal re‑training, allowing security teams to spot anomalies faster.
- Collective Defense: Security is a shared struggle across organizations. Generalizable models can learn from diverse data sets while preserving privacy, enabling communal resilience.
- Resiliency of Precision: Attackers evolve quickly; a foundation model can be re‑tuned to maintain accuracy under novel threat landscapes.
- Continuous Learning: By adapting to new logs and signals, foundation models reduce the risk of “catastrophic forgetting” of previously learned patterns.
The origin of foundation models
As security models have evolved from signature‑based detection (basic generalization) to machine learning (improved but still narrow), to deep learning (better representation, but often siloed), to foundation models (wide-ranging, fast adaptation), the ability to generalize has steadily climbed:
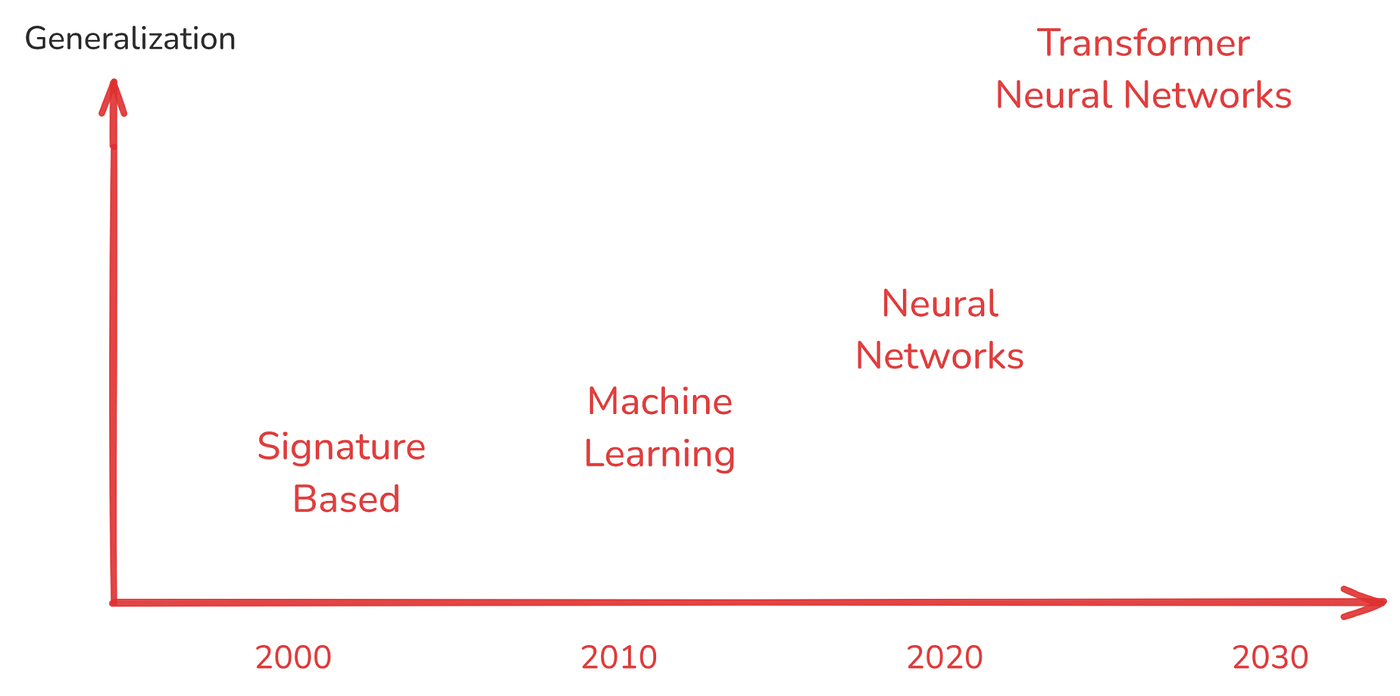
The architectures enabling this generalization have of course advanced enormously over time. It is worth emphasizing that while we can put neural networks on the same chart as traditional machine learning neural networks are fundamentally different. Neural networks learn patterns from data by adjusting the connections (weights) between neurons over many training iterations.
Transformers
In 2017, the paper Attention Is All You Need introduced the transformer architecture. Transformers use an attention mechanism to focus on different parts of the input sequence, enabling them to capture long-range dependencies more effectively than earlier neural networks like recurrent networks (RNNs). This shift dramatically improved performance in natural language processing, powering large language models (LLMs) like BERT, GPT, and others.
Scale & modern capabilities
Modern transformers are often massively scaled, with billions or even trillions of parameters. This enables them to:
- Encode vast amounts of knowledge from large corpora.
- Adapt to multiple downstream tasks with minimal training.
- Generalize beyond what smaller or older architectures could achieve.
Compared to traditional machine learning approaches (like logistic regression or random forests):
- Neural networks automatically discover representations from data, requiring less manual feature engineering.
- Transformers achieve state-of-the-art results in text, speech, and more — outperforming earlier CNN- and RNN-based models on tasks that demand contextual understanding or complex pattern recognition.
These breakthroughs in architecture design and scaling have paved the way for foundation models, which learn universal representations that can be quickly customized for tasks like cybersecurity anomaly detection, threat intelligence extraction, and more.
With foundation models at the core, organizations can reduce blind spots, adapt quickly to evolving threats, and share intelligence across a broad ecosystem — accelerating our collective learning and improving our collective defense.
