
MITRE: Discovery
A debate about AI's future direction surfaced recently when Yann LeCun left Meta AI to found AMI Labs in late 2025. The famous AI researcher Fei-Fei Li had moved earlier, starting World Labs in late 2024. Both companies pursue world models: AI systems that build internal representations of how environments behave over time. When we published our early explanation of why we built LogLM as a cyber world model, this industry momentum was already building.
The question arose naturally: how does our LogLM for cybersecurity relate to the Joint Embedding Predictive Architectures (JEPA) that LeCun and team developed at Meta? After deeper analysis, the answer became clear. LogLM functions as a vertical JEPA: an architecture sharing JEPA's core representational principles while extending them for cybersecurity's temporal, behavioral, and operational requirements.
What JEPA does
JEPA represents a departure from autoregressive and generative modeling. Instead of predicting pixels, tokens, or noise, JEPA trains models to predict latent representations of unseen or future portions of the world. Architecturally, this involves encoder-only transformers, a context pathway encoding observed information, a target pathway encoding masked information, and a predictor operating entirely in latent space.
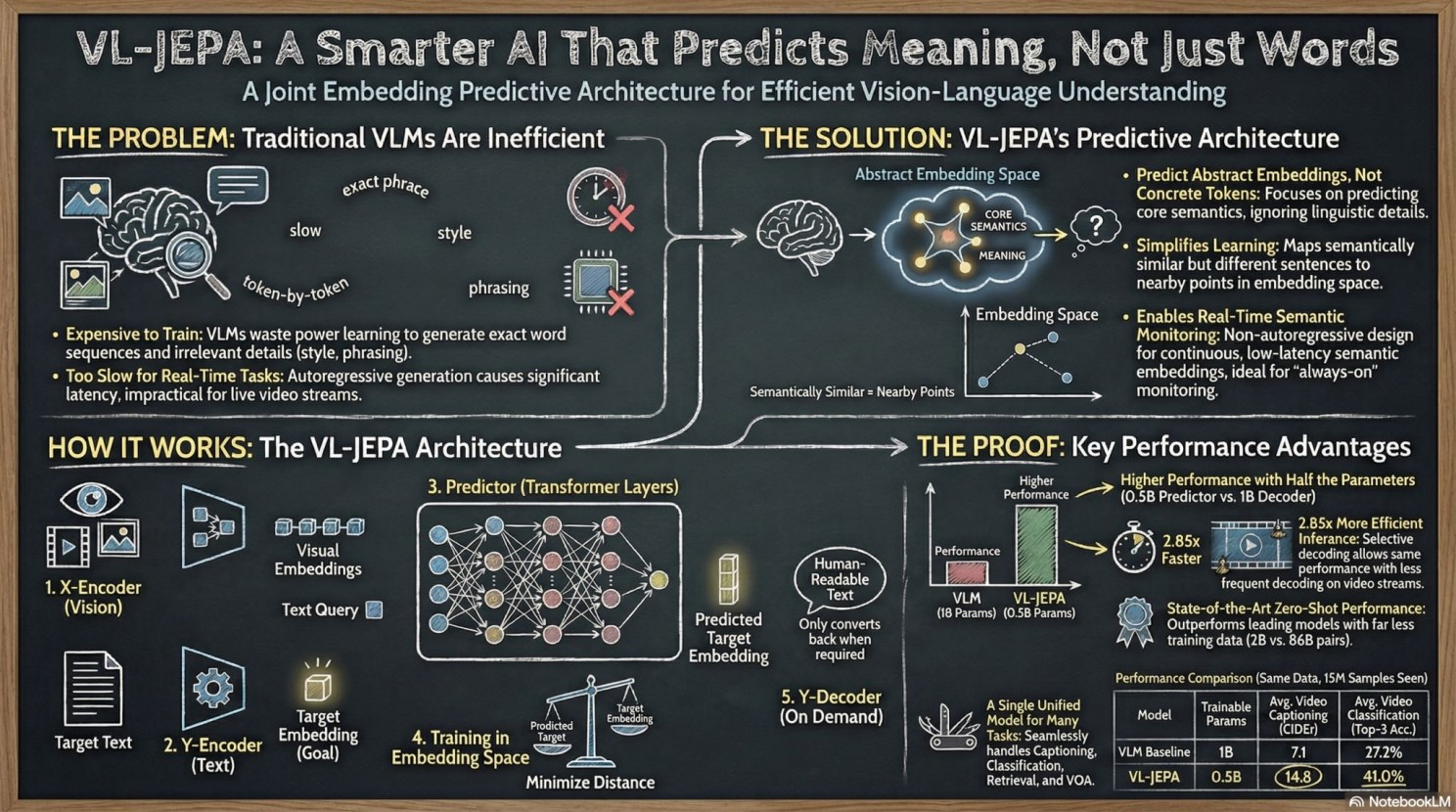
The central claim in the JEPA papers: intelligence emerges from learning invariant structure rather than reconstructing surface detail. JEPA's goal is abstraction, capturing the relationships and dynamics that persist across superficial variation.
LogLM architecture in brief
DeepTempo's LogLM is an encoder-only, transformer-based foundation model. We pre-trained on large-scale network and cloud telemetry, including flow logs, WAF logs, DNS logs, and related signals. The objective: learn the structure of normal behavior in enterprise environments so that meaningful deviations manifest clearly in embedding space.
Like JEPA, LogLM treats raw inputs as a means to learn latent structure, not as objects to be reproduced. Learning happens primarily in embedding space. The model's value lies in the structure of those embeddings and in related downstream capabilities, such as classification of behaviors into types of malicious activity.
This alignment reflects a shared belief: representation learning, not generation, forms the foundation of intelligence in complex systems. This matters for practical reasons. Today's automation-focused AI SOC solutions cannot fully understand behaviors in sufficient detail and nuance to become the brain of a future intelligent SOC. They lack the deep behavioral representations that enable true understanding.
Core similarities and key differences
The relationship between LogLM and JEPA becomes clearer when mapped directly:
Time as a first-class modeling dimension
One consequential difference between LogLM and general JEPA formulations lies in the treatment of time. In cybersecurity, time is not merely an ordering constraint. Attack behavior is often defined by pacing, duration, escalation, and silence as much as by individual events.
LogLM employs techniques to help the model learn extremely nuanced understandings of behavioral patterns. Without revealing specific implementation details now being protected via patents, these include engineered positional encodings and other techniques. We tested these across more than a year of intensive research. They are now being rapidly deployed and improved with design partners.
From a JEPA perspective, this expands the latent space to explicitly encode temporal structure. Time itself becomes part of what is being modeled rather than a secondary indexing mechanism.
Behavioral patches replace raw events
Vision Transformers replace pixels with image patches to learn object-level structure. LogLM replaces raw log events with behavioral patches so the model learns interaction motifs rather than vendor-specific syntax.
This design choice reinforces the JEPA principle of prioritizing invariant structure over surface detail, while adapting it to sequential, event-driven data.
Classifiers as downstream tasks
JEPA explicitly positions itself as a representation learner, leaving downstream tasks to separate components. LogLM follows this pattern directly. The foundation model produces high-dimensional embeddings that encode behavioral structure. Lightweight classifier heads are then applied as downstream tasks to interpret those embeddings.
These classifiers surface potential attacks, including behaviors similar to known techniques in the MITRE ATT&CK corpus, as well as previously unseen patterns that diverge from learned norms. Importantly, these heads do not replace representation learning; they operationalize it. LogLM's classifiers are the type of downstream tasks JEPA anticipates, adapted to the realities of production security systems.
From research architectures to operational world models
JEPA represents a growing consensus that future AI systems will be built around learned world models rather than pure generation. The recent momentum around world-model startups, including LeCun's AMI Labs, underscores how central this idea has become.
LogLM reflects the same shift, but in a different domain. Rather than modeling the physical world, it models the behavioral dynamics of enterprise systems. Rather than planning motion or control for robots and AGI, LogLM supports identification, isolation, investigation, interpretation, and response. The underlying architectural bet remains the same: intelligence comes from learning how systems evolve, not from predicting the next symbol.
LogLM as vertical JEPA
After deeper investigation, LogLM functions as a vertical JEPA: a joint embedding predictive architecture specialized for cybersecurity. LogLM shares JEPA's commitment to encoder-only transformers, latent-space prediction, and abstraction over reconstruction, while extending or grounding the approach for security detection use cases.
JEPA shows how to learn world models in principle. LogLM shows what those ideas look like when applied to a domain where behavior unfolds over time and where learned representations must ultimately inform real decisions about security threats.
The approach works. In production deployments, LogLM achieves detection accuracy exceeding 99 percent with false positive rates below one percent. At a major telecommunications provider, the system identified ransomware variants, fuzzing attempts, and DDoS patterns with high accuracy across attack categories it had never explicitly trained on. The model recognized attack logic: reconnaissance scanning patterns, exploitation timing, lateral movement behavioral timelines.
This zero-shot capability emerges from learning behavioral structure rather than memorizing specific attack signatures. When attackers develop new techniques using different tools, LogLM recognizes the underlying intent pattern. A reconnaissance behavioral timeline has distinctive structural characteristics regardless of which specific commands or protocols the attacker uses. The behavioral timeline structure reveals intent even when surface details change.
What this means for cybersecurity
The convergence of JEPA research and practical security applications like LogLM suggests a path forward for threat detection beyond traditional approaches. Rather than building ever-larger collections of signatures and rules, security systems can learn the fundamental structure of how systems operate and how attacks unfold.
This shifts detection from a reactive cataloging exercise to proactive understanding. The model brings behavioral context to every analysis. It understands which behavioral timelines are operationally normal for your environment and which represent malicious intent. This understanding cannot be achieved through rules or simple anomaly detection. It requires deep learning of behavioral structure at scale.
The practical implications: faster detection, fewer false positives, ability to catch novel attacks, and drastically reduced maintenance burden compared to rule-based systems. Security teams spend less time tuning thresholds and more time investigating actual threats.
Closing note
The research community's movement toward world models validates the architectural decisions we made in building LogLM. JEPA provides the theoretical foundation. LogLM demonstrates how those principles apply to cybersecurity's unique requirements: understanding behavioral timelines, detecting malicious intent, and operating reliably in production environments where mistakes have consequences.
If you are an organization interested in the future of threat detection, the technology exists now. LogLM can analyze your existing data to identify active threats that traditional detection systems miss.
Get in touch to run a 30 day risk-free assessment in your environment. DeepTempo will analyze your existing data to identify threats that are active. Catch threats that your existing NDRs and SIEMs might be missing!
